建国以来人均 GDP 增长情况
拜川普总统所赐,今年的国庆节国人过的非常振奋。
此生无悔入华夏,来世愿在种花家
这句话说出了很多人的心声。
情怀归情怀,我们从建国以来到底 成长的怎样
呢?闲话不说,直接上图,数据来源这里。
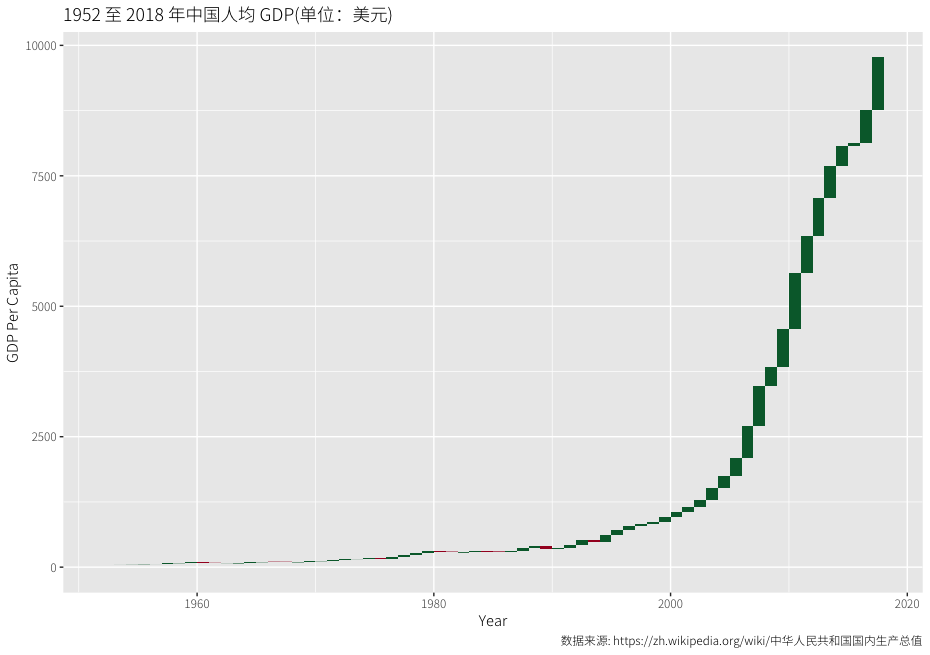
改革开放 40 年我们取得了非常傲人的经济成就,作为 80 后亲历者,图形化的结果还是震撼了我。从 04 年附近,人均 GDP 的增幅突然爆发出了一个向上的拐点,全球第二大经济体,这么巨大的体量居然还能做到如此,真心不容易!我们大部分普通老百姓即便是什么也没有做,生活水平也在跟着水涨船高,感谢我的政府!